Настройка производительности SQL-сервера
Эта заметка не претендует на полноту исследования темы производительности SQL-сервера, в любом случае хорошо бы прочитать Счётчики производительности SQL Server и Windows, Семь наиболее полезных счётчиков эффективности, Мониторинг эффективности MS SQL Server. Практические рекомендации, Использование таблицы sysperfinfo для разрешения проблем SQL Server. Вы легко найдете десятки подобных статей на русском языке и тысячи - на английском. Есть множество полезных статей в BOL - Оптимизация производительности базы данных tempdb
Я просто расскажу как я применил всю эту полезную информацию на практике для оптимизации кампутера с SQL-сервером, обслуживающим портал, на который ходит четверть миллиона посетилей в сутки (вероятно в следующий сезон будет еще раза в два больше). Этот кампутер имеет в основе своей адский SAS-контроллер, который обслуживает больше 10 ящиков, набитых дисками. Каждый видится как один SCSI-диск. Кроме SAS-контроллера кампутер имеет 16ГБ памяти, два четырехядерных ксеона и несколько обычных дисков.
1.Защита SQL-сервера
Первая задача, которую я решил - это защита этого кампутера от несанкционированного доступа из сети. Сделал я это обычным для себя способом - запихнул вовнутрь этого кампутера аппаратный фаервол.

2.Балансировка нагрузки дисковой подсистемы
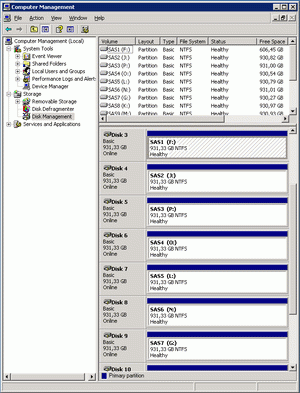
Балансировку нагрузки SAS-контроллера я обеспечил сплитированием всех основных баз - эту технологию я описывал на своем хомяке - Cекционирование графики при SQL-хранении.. В итоге каждая серьезная база у меня лежит на множестве дисков:
Кроме того, все базы разнесены по разным дискам, бекапы, индексы и так далее. Базы с записью работают даже не в Simple, а в BulkLogged. В итоге основной диск, который работает при работе SQL-сервера - это диск, на котором лежит TempDB. Именно он дергается на этом видео-ролике - когда резко возрастает размер дисковой очереди.
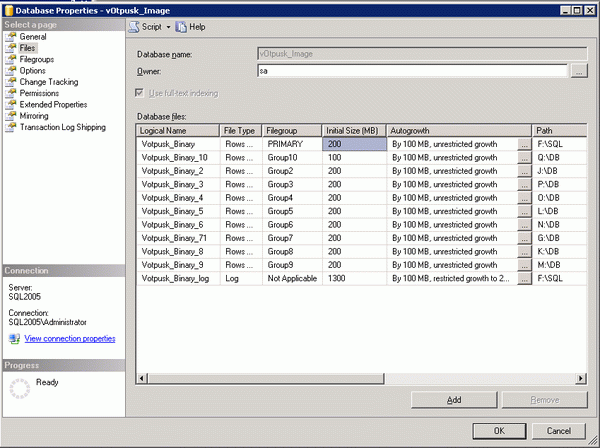
Понятно, что на таком загруженном диске вообще больше ничего не должно быть размещено. В принципе MS рекомендует создавать один файл TempDB для каждого ЦП на сервер. И поскольку диск с tempdb - это единственный реально загруженный диск у меня, я создам tempdb на 8 дисках.
3.Управление памятью
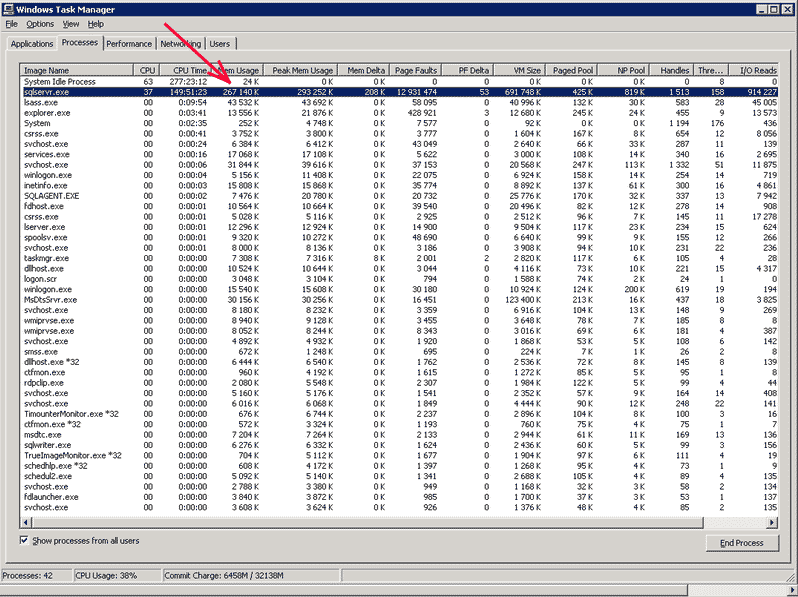
SQL-cервер я поставил в режим AWE, несмотря на то, что у меня все 64-х разрядное - и виндузня и сервер. Первый вопрос, в котором я хотел убедится, что SQL-серверу достаточно оперативной памяти. К сожалению, глюкавый микрасофт не сумел даже добится чтобы у него нормально работал Windows Task Manager, который взывается по Ctrl-Alt-Del. К сожалению, он показывает совершенно неадекватные цифры.
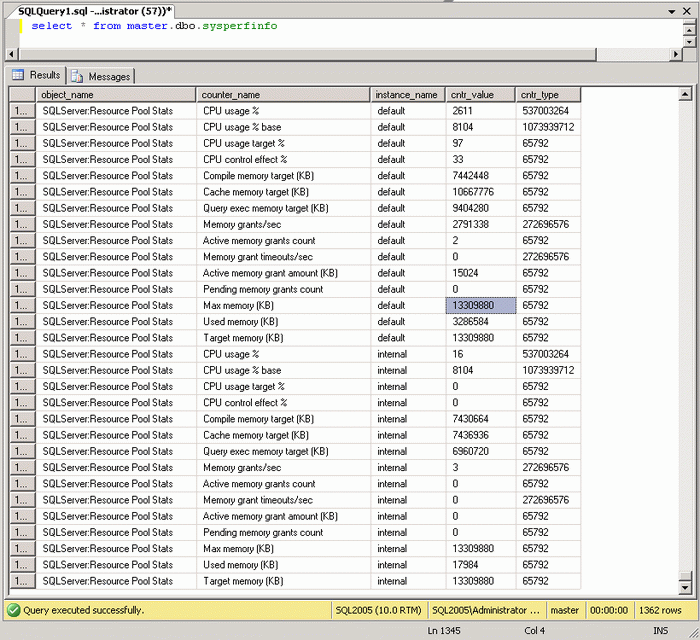
Есть еще и второй вариант тех же цифр, которые показывает вьюшка select * from master.dbo.sysperfinfo.
Есть и третий вариант тех же цифр - счетчики Perfomance. Все цифры разные. Каким цифрам верить - непонятно, но вроде бы микрософтовцы утверждают, что счетчики оснаски Pefomance у них получились менее глюкавые, чем остальные:
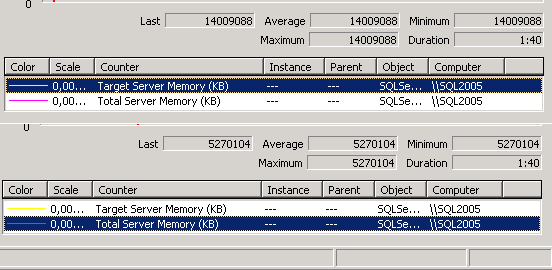
Если поверить счетчикам Performance, то можно увидеть что серверу у меня доступно 14GB памяти (что логично в-общем), но пожелал он из них занять 5,2GB. Это явная неадекватность микрософтовского алгоритма - иметь возможность занять ОЗУ кешем с данными, но не пользоватся ОЗУ. А постоянно подкачивать данные с дисков. У Оракла есть версия SQL-сервера, которая вообще умеет не дергать диски - просто считывает все данные в ОЗУ. Разумеется никакие индексы, факторы заполнения, сплитирование данных и прочие ухищрения просто не требуются в таком случае - доступ к данным в ОЗУ происходит мгновенно, не менее чем в миллион раз быстрее доступа к дискам (даже прикрученным к ацкому SAS-контроллеру).
Кроме этого непонятного трафика с дисками меня также смущает в микрософтовском алгоритме наличие огромных значений PageFault - этот счетчик означает, что требуемой странички с данными не оказалось в ОЗУ. Но в целом, поскольку я убедился, что памяти у меня существенно больше, чем SQL-сервер пожелал занять - на этом я посчитал и этот этап оптимизации завершенным.
4.Ожидания в сервере
Кроме памяти, обычно анализируется, что ожидает сервер. В моем случае видно, что у сервера нет никаких особых узких мест. Но в этом надо было убедится, хотя бы для того, чтобы перейти к следующему этапу оптимизации - построению индексов. Ведь трассу надо писать в сеть (на другой SQL) - чтобы не повлиять на оптимизируемый SQL. Для этого, как минимум надо убедится, что сеть не является самым узким местом сервера.
5.Построение индексов
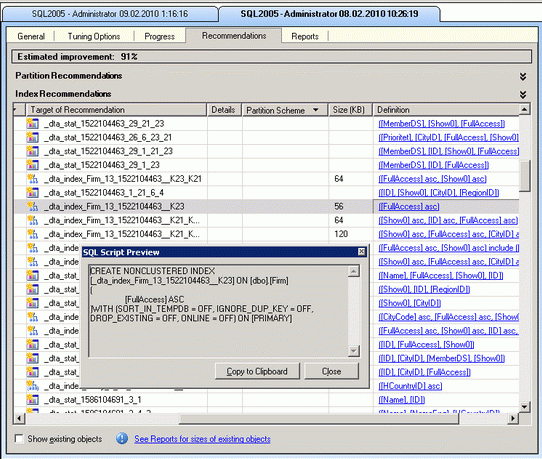
Ключом к эффективной работы SQL является нормальные индексы. Они позволяют сразу обратиться к нужной записи, а не путем перебора записей на диске. SQL 2005. Экзамен 70-431. Стр 121. "Чтобы найти строку в таблице, содержащей 2,5 миллиона строк, SQL Server должен просмотреть всего три страницы данных. И лишь когда в таблице станет более 300 миллионов строк, SQL Server придется просматривать четыре страницы для поиска нужной строки." Поэтому надо для начала выполнить все рекомендации Tuning Advisor'a.
Чтобы добится эффективной работы индексов - для начала надо правильно спроектировать базу. Грубо говоря - максимум ссылочных отношений, что позволяет оптимизатору сразу цеплять нужные связанные данные. Для сайта, который крутится на этом сервере - я сделал десяток таких диаграмм.
Об индексах надо помнить и на этапе SqL-программирования. Например, при записии индексы замедляют работу (их надо перестраивать). Поэтому на момент массовых записей в коде процедур их надо отключать. А таблы куда ведется всякая статистика портала - там индексы не нужны вообще, ведь запись туда идет всегда, а запрос сделает один раз в месяц администратор. Впрочем вопросов эффективного SQL-программирования много, не только индексы - например хинты WITH (NOLOCK) - чем их больше, тем все шустрее работает.
Индексы нуждаются и в правильной эксплуатации. Об обновлении статистики индексов - можно почитать здесь Использование статистики оптимизатором запросов Microsoft SQL Server 2005
6.Оптимизация тяжелых запросов.
Для оптимизации отдельных тяжелых запросов можно применить встроенные средства MS. Но есть и отдельные ацкие проги для этого, например SQL Shot. Но запросы, которые нельзя оптимизировать, скажем до нескольких секунд - от них надо отказаться вообще. Как это сделать?
Я делаю кеширование таких тяжелых запросов на самом верхнем прикладном уровне. Для этого все тяжелые отборы просто запускаются в задании, а юзер с сайта просто получает не вполне актуальный, но мгновернный результат. Таким образом в моих проектах все тяжелые запросы выведены в джобы и на реактивность портала не влияют.
Вот пример. На сборке Сборка для работы с данными стандартных ASP.NET-профилей на уровне SQL сделана вот такая процедура, которая вызывается в задании. Таким образом пользователь сайта мгновенно получает результат запроса, который считается часами.
7. Общее снижение нагрузки на SQL
Вот несколько моих любимых методов:
1. Вынос всех что можно запросов в Application_start и Session_start. Например, вот фрагмент global.asax. Как видите, нужные много раз рекордсеты я сделал еще при старте сессии. А на страничках я просто достаю рекордсеты из памяти без обращения к SQL.
2. Когда очень много курсорных запросов RS.Movenext есть смысл получить весь рекорсет сразу с FOR XML. Производительность тут увеличится не в каждой ситуации, но это тоже может быть выходом по снижению нагрузки на SQL.
3. Еще метод снижения нагрузки - сгенерить заданием SQL готовые html-фрагменты с комбобоксами и включить этот готовый фрагмент асповской директивой <!--#include (или литералом).
4. Перенос всех типовых заданий сайта (Выполнение периодических задач в ASP.NET) на ночное время.
После настройки производительности SQL-сервера ну забудьте наладить бекапирование данных.
Device context:
Servers context:
 )
)
|
|