| Журнал "Мир Internet" http://www.iworld.ru/ |
| #5 (68) май 2002 http://www.iworld.ru/magazine/index.phtml?do=show_number&m=94701987 |
X.500 На пути к информационному раю
Когда-то давным-давно, еще в прошлом веке, было сделано
изобретение, изменившее мир. И имя ему – "почта по RFC822". Изобретение
это было оценено по достоинству и тут же отнесено к разряду жизненно
необходимых. Но как водится, вскоре нашлись люди, посмевшие утверждать,
что можно было сделать почту и получше, и даже придумали свою версию
стандарта для системы обработки почты, получившую название X.400. "Мир
Internet" уже писал на эту тему. Но, к сожалению, в силу объективных и
субъективных причин судить о достоинствах и недостатках этого стандарта
до сих пор может лишь небольшая часть интернет-сообщества.
Однако
в этой статье речь пойдет о другом. Появление на свет X.400
ознаменовало собой начало истории другого изобретения, которое имеет
все шансы изменить мир еще раз...
Дмитрий Рожков
Проблема
Самый главный недостаток систем обработки почты на основе X.400, который сразу бросается в глаза, – это вид адреса электронной почты. Вот его пример:
cn=Dmitry Rojkov, prmd=Piter, admd=ATT, c=RU
Сложно не согласиться с утверждением, что адрес вида rojkov@piter.com запоминается гораздо лучше. Однако проблема подсказывает решение. Тем более что им давно пользуются телефонные компании: стоит ли утруждать свою память заучиванием любых мало-мальски полезных телефонов, если все телефонные номера можно свести в единый справочник, который всегда под рукой и где все имена абонентов телефонной сети для простоты поиска сгруппированы по месту жительства и упорядочены по алфавиту. Причем запись об абоненте может кроме номера телефона содержать и другие полезные сведения.
Очевидно, что подобный справочник был бы весьма полезен и для пользователей электронной почты. Стандарт (а точнее, рекомендации Международного телекоммуникационного союза – ITU), описывающий работу электронного справочника, получил название X.500. Этот стандарт появился, конечно же, не на пустом месте – у него есть предшественники, опыт использования которых был учтен в ходе разработки. Среди них важное место занимает протокол finger, при помощи которого пользователи ОС Unix получают информацию друг о друге.
Finger
Чтобы воспользоваться услугами finger-сервера, надо всего лишь вызвать из командной строки программу-клиент и передать ей в качестве параметра имя сервера, на котором зарегистрирован интересующий пользователь, и имя его системного аккаунта:
$ finger rojkov@castle.piter-press.ru
В ответ получим что-то наподобие:
Login name: rojkov | In real life: Dmitry Rojkov |
Directory: /home/rojkov | Shell: /bin/sh |
On since: Mar 12 10:39:42 | 4 hours 52 minutes idle time |
Plan: Today I'll be available till 17:00 | |
Home: 555-1234 | |
Для небольшой программы это достаточно информативный ответ в удобном формате. Впрочем, удобством формата вывода все достоинства finger и ограничиваются, все остальное – недостатки: во-первых, finger реализован далеко не во всех ОС; во-вторых, информация о пользователе привязана к конкретному серверу: с одной стороны, нужно знать, на каком именно сервере зарегистрирован интересующий пользователь, с другой – самому пользователю необходимо следить за тем, чтобы информация о нем была согласованной на всех серверах, где он зарегистрирован. Кроме того, нет возможности выполнить поиск всех пользователей, чей домашний телефон начинается, допустим, на 333.
Whois
Другим примером справочника может служить утилита whois, к помощи которой чаще всего прибегают системные администраторы, чтобы определить, какой организации принадлежит тот или иной IP-адрес или доменное имя. Набрав в командной строке
$ whois piter.com
мы тем самым поручаем утилите запросить из базы данных всю имеющуюся информацию о домене piter.com. Получаемые данные, в частности, содержат:
- название организации, зарегистрировавшей домен;
- название организации или имя персоны, которой он принадлежит;
- физический адрес владельца домена;
- электронные адреса для контакта с владельцем и т. д.
Сам сервер базы данных находится в Калифорнии и доступен всему миру через Интернет. Его адрес фиксирован, и поэтому нет нужды указывать его в параметрах утилиты whois (хотя такая возможность имеется). База данных поддерживается организацией с длинным названием Defence Data Network Network Information Center (DDN NIC) или просто NIC.
Существование сервиса whois стало возможным благодаря тому, что в руках NIC сосредоточен весь контроль над выдачей свободных IP-адресов и выдача адреса увязана с регистрацией этого события в базе данных. Таким образом, централизованное ведение базы данных избавляет whois от недостатков, присущих finger: запись об объекте существует в одном экземпляре, а потому противоречивость результатов запросов об одном и том же объекте исключена. Кроме того, поиск информации можно вести по нескольким критериям: IP-адрес, доменное имя, имя владельца и т. д. Однако следствием централизации, наряду с достоинствами, являются и недостатки. Объем централизованной базы данных центрального сервера имеет технологические пределы, при достижении которых время отклика в период пиковых нагрузок на базу может значительно увеличиться. Еще неприятнее, что из-за неисправности сервера или канала подключения к Сети доступ к службе может полностью пропадать. Очевидным требованием к глобальному справочнику, призванным исключить подобную ситуацию, является наличие распределенной архитектуры, в результате чего информация, с одной стороны, организована в единую структуру, а с другой – распределена на многих серверах по всему миру, и выход из строя одного из них не приводит к недоступности сервиса в целом.
DNS
Примером распределенного справочника является служба доменных имен DNS, основное предназначение которой – хранить информацию о соответствии IP-адресов доменным именам и наоборот, а также множество других полезных сведений, например адреса сервера почтового обмена для домена. Для повышения надежности и производительности в системе активно используется кэширование, репликация данных с первичных серверов на вторичные и делегирование обязанностей по обслуживанию доменов нижних уровней другим серверам.
Все эти возможности делают DNS очень быстрой и чрезвычайно надежной службой, но, тем не менее, и у нее есть ограничения, не позволяющие ей стать полноценным справочником. Во-первых, в DNS сильно ограничены возможности поиска, а во-вторых, набор поддерживаемых DNS типов данных зафиксирован в коде DNS-серверов, и без правки исходного кода (и последующего тотального обновления ПО) добавить новые типы данных невозможно1.
Требования
Таким образом, предшествующий опыт позволил сформулировать требования, предъявляемые к идеальному справочнику. Он должен иметь:
- децентрализованное управление; каждый сервер отвечает только за свою локальную часть базы справочника, чтобы обновление данных и сопровождение можно было выполнять немедленно;
- мощные возможности поиска, дающие пользователям возможность создавать запросы произвольной степени сложности;
- единое глобальное пространство имен по аналогии с DNS;
- структурированный информационный каркас, допускающий локальные расширения;
- стандартный интерфейс, единый протокол доступа. Приложения, нуждающиеся в ресурсах справочника, должны производить запросы, используя стандартизированный протокол, одинаковый для всех платформ.
Всем этим требованиям как раз и отвечают системы, построенные по стандарту X.500. Во второй части статьи мы кратко рассмотрим принципы работы систем X.500, которые с этого момента будем называть Справочником2 с заглавной буквы, обозначая тем самым их глобальный характер.
Схема Справочника
Вся информация, хранящаяся в Справочнике, представлена в виде записей. Запись – это отображение в Справочнике объекта реального мира: страны, организации, подразделения, персоны и т. д. Каждый такой объект характеризуется свойствами, то есть атрибутами, которые могут принимать значения согласно определенному для каждого атрибута синтаксису. Например, для номера телефона может быть задан синтаксис ddd-dd-dd, где d – цифра от 0 до 9. Некоторые атрибуты могут быть обязательными для объекта (например, фамилия для персоны), другие – факультативными (допустим, имя супруга).
Однотипные объекты объединены в классы объектов или, точнее, инстанцируются3 от одного класса объектов. Классы объектов организованы в иерархию. Создавая новый класс на основе уже имеющегося, можно расширить состав его атрибутов. На вершине иерархии находится базовый класс, а под ним – его классы-потомки, наследующие атрибуты у классов-предков. Тем, кто изучал основы объектно-ориентированного дизайна, все это должно быть хорошо знакомо (рис. 1).
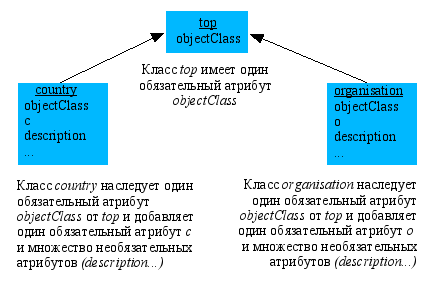
Рис.1 Пример иерархии классов (RFC1309)
Формальное определение иерархии классов объектов, атрибутов и их синтаксиса называется схемой Справочника. Схема как раз и является тем самым структурированным информационным каркасом, который допускает локальные расширения. В принципе, любой системный администратор может составлять собственные схемы под свои нужды, однако, если мы хотим получить действительно глобальную информационную службу, необходима унификация схем. Именно эта потребность вызвала появление на свет документов, определяющих стандартные схемы. Например, схема, служащая для поддержки функционирования самой службы X.500, определена в рекомендациях X.521, схема для поддержки почты X.400 описана в X.402. Кроме того, в документе RFC1274 определены еще две схемы, весьма полезные для глобального Справочника, – COSINE и Internet X.500, а также четко описан механизм изменения существующих и добавления новых стандартных схем, когда в этом назревает необходимость.
Дерево записей
Вся полезная информация, хранящаяся в Справочнике, образует информационную базу Справочника – DIB (Directory Information Base), которая организована в виде иерархического справочного информационного дерева – DIT (Directory Information Tree). DIT – это ключевой элемент в понимании работы Справочника X.500, поэтому рассмотрим его подробней.
Каждая запись Справочника занимает определенное положение в DIT. Записи, у которых нет подчиненных записей, – это листья дерева. Листьями чаще всего оказываются записи о людях. Все остальные записи – это узлы дерева. Нижние узлы дерева подчинены вышестоящим, а самые верхние подчинены одному-единственному узлу, называемому корнем. В целом иерархия записей очень напоминает организацию файлов в файловой системе: корневой каталог, подкаталоги и находящиеся внутри них файлы.
Каждая запись дерева содержит атрибут, который по совместительству является относительным уникальным именем записи – RDN (Relative Distinguished Name)4. Таким атрибутом, как правило, является имя объекта или его уникальный идентификатор. Уникальность этого имени "относительна" в масштабе всего Справочника, поскольку на разных ветвях DIT могут оказаться записи с одинаковыми RDN, подобно тому, как в разных подкаталогах одной файловой системы могут оказаться файлы с одинаковыми именами. И так же, как путь к файлу определяет его полное уникальное имя в пределах файловой системы, последовательность RDN-записей на пути от корня до нужной записи образует уникальное имя (DN) этой записи (рис. 2).
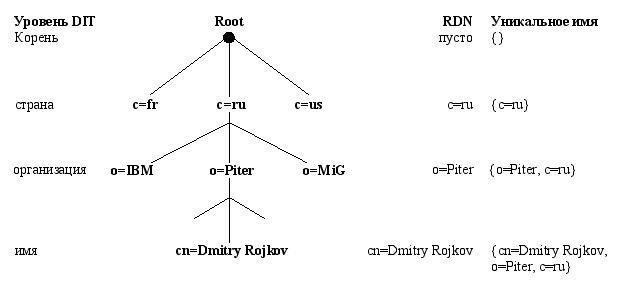
Рис.2 Фрагмент иерархии DIT
Стандарт X.500 допускает использование псевдонимов, когда два различных DN указывают на одну и ту же запись. Пользователи Unix заметят, что это очень похоже на использование файлов-ссылок. Вот таким образом DIT создает глобальное пространство имен, имеющее много общего с DNS и способное в перспективе заменить его.
Схема Справочника вместе с пространством имен (иерархией именованных записей) образуют информационную модель службы X.500. Однако для построения рабочей системы требуется реализация еще двух механизмов: модели каталогов и модели безопасности. Модель безопасности служит для того, чтобы возвращаемая Справочником информация была достоверной, а доступ к ней был разграничен. Модель каталогов описывает, как хранящаяся в логически едином Справочнике информация распределяется по разным физическим серверам и с помощью каких протоколов эти серверы общаются друг с другом и предоставляют информацию клиентскому ПО. Подробнее об этих моделях рассказывается во врезке. Нам же сейчас важно знать, что в основе модели каталогов службы X.500 лежит сложный и громоздкий протокол – протокол DAP (Directory Access Protocol). А клиенты для доступа к информации Справочника могут использовать его упрощенный вариант – LDAP (Lightweight Directory Access Protocol).
Применение
Теперь настало время сказать о применении Справочника. Как уже упоминалось, записи о персонах кроме имени могут содержать множество атрибутов: телефон, адрес электронной почты и др. Причем совсем не обязательно, чтобы электронный адрес был в формате X.400. Обычный RFC822-совместимый "e-mail" тоже имеет право находиться в Справочнике.
Кроме того, X.500 был задуман не только ради организации службы "белых страниц", но также и для организации инфраструктуры управления открытыми ключами. Несмотря на то что алгоритмы шифрования с открытым ключом и электронной подписи разработаны уже давно, люди недостаточно активно пользуются ими для частной и деловой переписки. Все дело в трудностях, связанных с обменом открытыми ключами. А между тем, открытый ключ также может являться атрибутом любой записи в Справочнике наряду с адресом электронной почты, фотографией и названием любимого напитка. Появляется принципиальная возможность сделать шифрование личной почты прозрачным для пользователей и окружить тайну переписки таким барьером, который был бы непреодолим даже для спецслужб, а автоматическое удаление неавторизованных, анонимных писем может стать мощным оружием против столь ненавистного спама.
Перспективы
Возможности применения Справочника X.500 не ограничиваются лишь поддержкой почтовых систем, для чего он был изначально разработан. Описанный в RFC1430 стратегический план развития справочного сервиса включает хранение и реализацию поиска любых полезных ресурсов (принтеры, сетевое оборудование и т. д.), хранение конфигурационной информации, организацию ее в высокоуровневые справочники для поддержки управления инфраструктурой Интернета, хранение информации о местонахождении статей в информационных архивах. А в далекой перспективе планируется создание электронного варианта пока еще бумажного каталога "Желтые страницы", но уже в мировом масштабе и с возможностью для фирм самостоятельно редактировать устаревшие данные. Вся эта радужная картина способна вскружить голову любому человеку, чья повседневная жизнь так или иначе связана с Интернетом. Однако, как это часто бывает, реальность вносит свои коррективы.
Так, например, до сих пор не появилось достаточно быстрой и надежной реализации протокола DAP для стека TCP/IP и вряд ли появится, поскольку X.500 DAP не создавался для этого стека, и для его работы требуется дополнительное ПО сопряжения5. Впрочем, появление LDAP версии 3 дает надежду, что необходимость в DAP отпадет, так как аутентификация, шифрование, целостность данных и их репликация будут поддерживаться LDAP, который как раз и создавался для работы в TCP/IP.
Другим сдерживающим фактором является то, что для построения нового пространства имен требуется наличие специальной организации, регистрирующей имена, да и сама процедура выдачи имени пока не вполне очевидна. Например, какое имя будет правильнее зарегистрировать в Справочнике – официальное Piter Join Stock Company или более известное Piter? А к какой стране отнести транснациональную компанию? Однако выход из этой ситуации было предложено искать в использовании уже существующей инфраструктуры регистрации доменных имен и введении нового класса объектов в схему Справочника – domainComponent с одним обязательным атрибутом dc, в котором содержится часть доменного имени. Тогда вид DIT изменится на тот, что изображен на рис. 3.
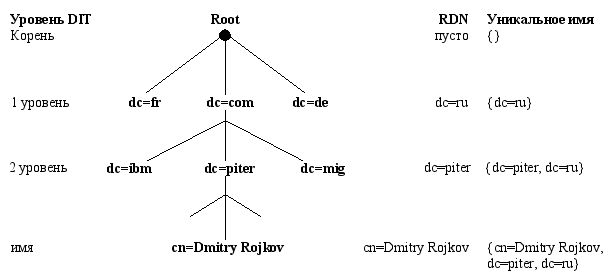
Рис.3 К вопросу о возможности интеграции DIT и DNS
В этом случае уникальные имена записей в DIT будут строиться не из набора атрибутов c, o, ou, а из последовательности атрибутов dc по пути от корня иерархии к объекту. Атрибуты же, определяющие страну и организацию, будут играть второстепенную роль. Таким образом, верхняя часть иерархии Справочника будет унаследована от DNS, а сам Справочник явится надстройкой над DNS. Трудно сказать, сможет ли когда-нибудь такая служба полностью вытеснить DNS, но подобная организация DIT может оказаться полезной для управления конфигурационной информацией о домене, которая бы просто загружалась из Справочника в DNS-сервер с помощью протокола передачи зоны (Zone Transfer Protocol).
Несмотря на все сложности, развитие справочного сервиса не останавливается. Пользу от применения Справочника можно получить не только в масштабе всей Сети, но и в локальных сетях предприятий. Он позволяет реализовать хорошо масштабируемый единый механизм аутентификации пользователей локальных сервисов, будь то доступ к данным разнородных СУБД предприятия, к почте, к интранет-серверам или другим серверам приложений. Благодаря справочнику образуется однородная среда, в которой пользователю достаточно всего лишь раз пройти процедуру аутентификации, чтобы получить доступ ко всем ресурсам, работать с которыми он имеет право согласно локальным политикам безопасности. Из других преимуществ, которые дает применение Справочника, можно назвать, например, простоту управления маршрутизацией почты и единое управление конфигурационной информацией рабочих станций локальной сети6. Все это подвигло многих производителей выпустить на рынок свои реализации LDAP-серверов. Среди них и Netscape Directory Server, и Novell NDS, и, конечно же, Microsoft Active Directory. Сообщество Open Source также обзавелось своей реализацией – OpenLDAP.
Сейчас трудно судить, насколько хорошо будут стыковаться между собой все эти продукты, но не исключено, что из объединения локальных островков Справочника, из маленьких веточек вырастет огромное дерево.
Дмитрий Рожков,
rojkov@piter.com
1 Последнее обстоятельство, например, сильно затрудняет использование протокола IPSec для шифрования трафика между интернет-узлами в глобальном масштабе. Ведь IP-адреса, в принципе, можно транслировать не только в доменные имена, но и в открытые ключи, однако такой тип данных до сих пор не предусмотрен в реализациях DNS, которые используются в настоящее время на большинстве DNS-серверов.
2 Встречающийся в русскоязычной литературе термин "служба каталогов" мне нравится меньше, потому что он не подчеркивает справочной сути описываемой технологии.
3 То есть являются экземплярами объектов определенного класса.
4 В качестве RDN можно использовать также комбинацию атрибутов.
5 Основой функционирования X.500, по замыслу его создателей, должен был стать стек протоколов в модели OSI. Стек OSI – это не просто абстрактная семиуровневая модель, которую принято изображать на первых страницах всех учебников по сетевым технологиям. Существует множество реализаций этого стека, которые по ряду объективных причин так и остались невостребованными.
6 То есть локальный справочник X.500 – это потенциальная замена системам, подобным NIS.
Полезные ссылки
www.applmat.ru/metacomputing/ism99.html – использование службы директорий LDAP для предоставления метаинформации в глобальных вычислительных сетях.
www.umich.edu/~dirsvcs/ldap/doc – документация на сайте университета штата Мичиган.
www.itu.org – сайт Международного телекоммуникационного союза.
www.netscape.com/directory/v4.0/faq.html – FAQ по продуктам Netscape.
www.openldap.org – сайт проекта OpenLDAP.
www.dante.net/nameflow – NameFLOW Directory Service.
Несколько хороших статей:
www.osp.ru/lan/2001/05/038.htm – "LDAP в середине пути".
www.osp.ru/nets/2000/09/072.htm – "Распутывая клубок LDAP".
www.osp.ru/lan/1999/10/009.htm – "Каталоги и Internet".
Модель каталогов
Модель каталогов (directory model) описывает, каким образом Справочник хранит информацию и как пользователи получают доступ к информации Справочника. Модель состоит из двух компонентов: пользовательского агента Справочника – DUA (Directory User Agent), запрашивающего Справочник от имени пользователя, и системного агента Справочника – DSA (Directory System Agent), который обеспечивает хранение некоторой части DIB и в то же время может являться точкой доступа к Справочнику для DUA. Каждому DSA делегируется своя область ответственности за хранение той или иной ветви DIT. Например, DSA1 может хранить записи, находящиеся ниже узла ou=Sales, o=Piter, c=ru, а DSA2 – отвечать за листья на ветке ou=Stores, o=Piter, c=ru. И администрировать их будут разные люди. При этом обязательно будет существовать DSA, обслуживающий корень дерева. Все это очень похоже на то, как работают серверы DNS.
Когда пользователю нужна информация о номере телефона сотрудника другой фирмы, он поручает сделать запрос об этом DUA. Точкой доступа для DUA, скорее всего, будет являться DSA, обслуживающий локальную часть DIT, в которой никаких сведений о постороннем сотруднике, разумеется, нет.
В этом случае возможны два варианта развития событий:
- DSA возвращает DUA ссылку на вышестоящий DSA, который может либо вернуть требуемые данные, если этот DSA компетентен в данной области DIT, либо вернуть ссылку на следующий DSA – вышестоящий или подчиненный;
- DSA сам делает запросы к другим DSA по цепочке и возвращает результат DUA.
Таким образом, с точки зрения пользователя доступ к данным осуществляется прозрачно.
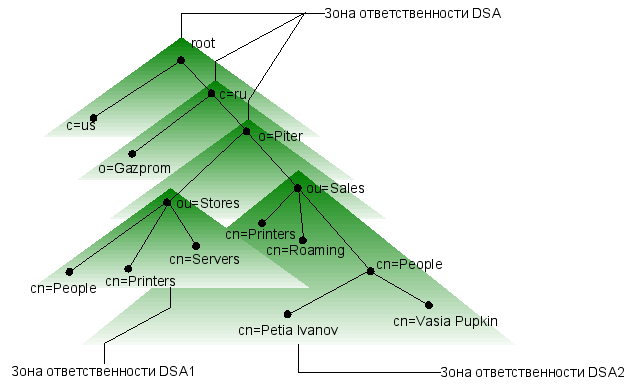
Наряду с обеспечением децентрализации для повышения производительности и надежности работы Справочника рекомендации X.500 предусматривают возможность репликации данных с одного DSA на другой и синхронизации реплик, а также возможность кэширования. Для реализации всех этих возможностей был создан протокол доступа к Справочнику – DAP (Directory Access Protocol). DAP – это язык, на котором DSA общаются между собой (на самом деле X.500 определяет целый набор протоколов, в котором роль DAP сводится к взаимодействию DSA с DUA, но почему-то этот факт не всегда находит отражение в соответствующей литературе). Однако, как показал опыт, этот протокол очень ресурсоемкий и трудно реализуемый, поэтому в университете штата Мичиган был разработан его облегченный вариант – LDAP (Lightweight Directory Access Protocol), или, как его еще иногда называют, "DAP на диете". Основное его предназначение – предоставление стандартного интерфейса к данным, хранящимся в DSA. Но развитие LDAP продолжается, и постепенно он приобретает дополнительную функциональность.
Модель безопасности
Модель безопасности определяет два типа безопасного доступа DUA к данным Справочника: простая аутентификация по паролю и сильная аутентификация, в основе которой лежит использование асимметричных ключей. Последний способ используется DSA для аутентификации друг друга для исключения атак типа "man-in-the-middle" и описан в рекомендациях X.509. Кроме того, могут быть использованы так называемые списки управления доступом для определения прав доступа к тем или иным атрибутам записей. Например, атрибут userPassword не должен быть доступен для чтения и тем более для записи посторонним пользователям.
| #5 (68) май 2002 http://www.iworld.ru/magazine/index.phtml?do=show_number&m=94701987 |
| Журнал "Мир Internet" http://www.iworld.ru/ |